
大数据共66篇 第3页
大数据(big data),是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
排序
大数据的产生和作用,大数据的产生过程

大数据是信息通信技术发展积累至今,按照自身技术发展逻辑,从提高生产效率向更高级智能阶段的自然生长。无处不在的信息感知和采集终端为我们采集了海量的数据,而以云计算为代表的计算技术的不...
离散化和数值概念层次树简介
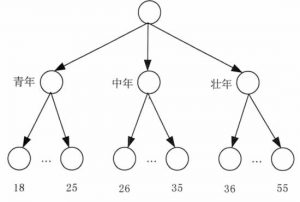
离散化技术方法可以通过将属性(连续取值)域值范围分为若干区间,来帮助消减一个连续(取值)属性的取值个数。可以用一个标签来表示一个区间内的实际数据值。在基于决策树的分类挖掘中,消减属...
Hadoop MapReduce工作流程介绍
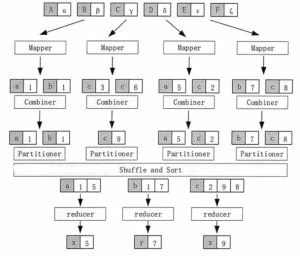
MapReduce 就是将输入进行分片,交给不同的 Map 任务进行处理,然后由 Reduce 任务合并成最终的解。 MapReduce 的实际处理过程可以分解为 Input、Map、Sort、Combine、Partition、Reduce、Outpu...
MapReduce编程实例:单词计数
本节介绍如何编写基本的 MapReduce 程序实现数据分析。本节代码是基于 Hadoop 2.7.3 开发的。 任务准备 单词计数(WordCount)的任务是对一组输入文档中的单词进行分别计数。假设文件的量比较大...
Spark Streaming编程模型,DStream 的操作流程和使用方法
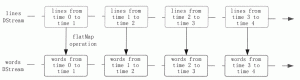
本节将介绍 Spark Streaming 的编程模型,包括 DStream 的操作流程和使用方法。 DStream 的操作流程 DStream 作为 Spark Streaming 的基础抽象,它代表持续性的数据流。这些数据流既可以通过外...
MapReduce执行流程和Shuffle过程
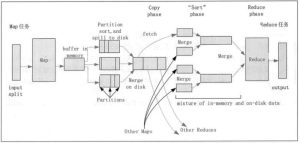
本节将对 Hadoop MapReduce 的工作机制进行介绍,主要从 MapReduce 的作业执行流程和 Shuffle 过程方面进行阐述。通过加深对 MapReduce 工作机制的了解,可以使程序开发者更合理地使用 MapReduc...
Hadoop HBase数据库的详解介绍及使用范例
这里我们继续深入详细了解HBase,并通过一个实例使用HBase进行数据操作。 1. HBase数据模型HBase的数据模型主要包含: - Table:对应关系数据库中的表,用于存储类似数据。 - Row:对应表中的行,根据...
Spark生态圈简介
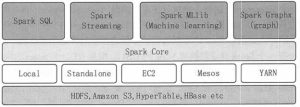
Spark 生态圈是加州大学伯克利分校的 AMP 实验室打造的,是一个力图在算法(Algorithms)、机器(Machines)、人(People)之间通过大规模集成来展现大数据应用的平台。 AMP 实验室运用大数据、...
MapReduce实例分析:单词计数
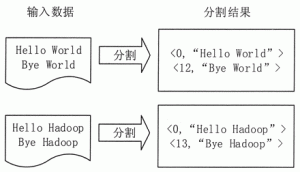
单词计数是最简单也是最能体现 MapReduce 思想的程序之一,可以称为 MapReduce 版“Hello World”。单词计数的主要功能是统计一系列文本文件中每个单词出现的次数。本节通过单词计数实例来阐述...
Spark总体架构和运行流程
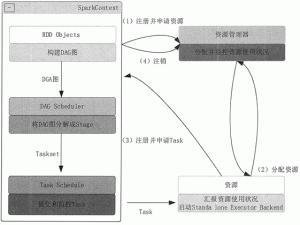
本节将首先介绍 Spark 的运行架构和基本术语,然后介绍 Spark 运行的基本流程,最后介绍 RDD 的核心理念和运行原理。 Spark 总体架构 Spark 运行架构如图 1 所示,包括集群资源管理器(Cluster ...







