
服务器共1282篇 第78页
服务器英文名称为“Server”,指的是在网络环境中为客户机(client)提供各种服务的、特殊的专用计算机。在网络中,服务器承担着数据的存储、转发、发布等关键任务,是各类基于客户机/服务器 (C/S) 模式或 B/S 模式网络中不可或缺的重要组成部分。
排序
IIS6下配置fastcgi的php的教程
在IIS6下配置FastCGI的PHP,需要以下几个步骤: 1. 安装PHP 首先需要在IIS所在的Windows服务器上安装PHP,安装过程请参考PHP官网文档。安装完成后,会得到php.ini,php5isapi.dll等文件。 2. 配置PHP...
301重定向:IIS服务器网站整站301永久重定向设置方法(阿里云)
301永久重定向能够将一个网站URL永久重定向到另一个网站URL,用于网站迁移或域名更改场景。本文将以阿里云服务器上的IIS网站为例,介绍如何设置整站301永久重定向。 1. 登录阿里云控制台,进入IIS...
服务器IIS安全加固防御方法及步骤
这里给出IIS服务器安全加固的详细操作步骤: 1. 更新IIS补丁并升级到最新版本打开IIS管理器,选择“IIS”节点,在右侧点击“检查更新”按钮,安装最新补丁。升级IIS版本,打开“程序和功能”,选择“I...
IIS实现反向代理时Cookie域的设置方法 什么是反向代理
反向代理 神马是反向代理?指以代理服务器来接受Internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给Internet上请求连接的客户端,此时代理服务器对外...
IIS 7.5中http转https的实战记录,图文教程
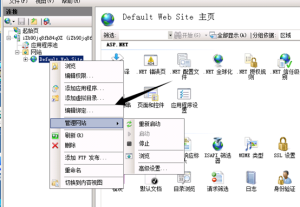
什么是https SSL(Security Socket Layer)全称是加密套接字协议层,它位于HTTP协议层和TCP协议层之间,用于建立用户与服务器之间的加密通信,确保所传递信息的安全性,同时SSL安全机制是依靠数...
iis7.5中让html与shtml一样支持include功能,添加模块映射
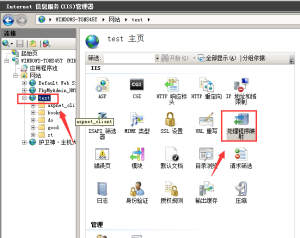
刚开始弄得时候,发现了很多错误,其实很简单,参考shtm原来的设置就可以了 前提条件: ServerSideIncludeModule的安装: 在安装iis的时候选择上该服务(“在服务端包含文件”,选项)即可,如...
IIS7~IIS8.5删除或修改服务器协议头Server
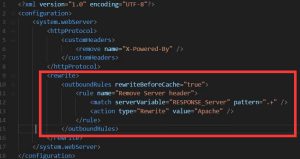
需求:在IIS 7、7.5、8.0、8.5和ASP.NET中删除HTTP响应标头,修改或隐藏IIS 7、7.5、8.0、8.5的Server头信息。 解决方案:使用url-rewrite规则 1、先安装 http://www.iis.net/downloads/microso...
在删除并重新安装 IIS 之后修复 IIS 映射
如果在运行SDK或VisualStudio安装程序时没有安装IIS,或者在运行SDK或VisualStudio安装程序之后卸载并重新安装了IIS,那么这些设置将不正确。试图查看ASP.NET页时会遇到意外的情况。 当您试图在...
网站加速CDN、SCDN、DCDN有区别?如何选择?
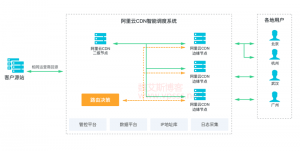
1、CDN 是网站中最常用的加速功能。通过分布式服务器布局,把网站业务内容缓存到各地的云服务器中,供访客就近访问。所以使用了 CDN 的网站业务,打开速度特别快。 局限性在于普通CDN加速只给静...
电商平台为什么要使用独立服务器托管?有什么好处?

电商平台已经成为产品的重要渠道之一,电商行业也是各行各业的发展趋势了。那么搭建电商平台自然需要服务器和空间作为支撑。一般来说,电商行业的大多平台都会选择独立的服务器,主要是因为电商...







