
函数共999篇 第46页
函数是预先定义的功能块(由代码组成)。我们编写函数的目的通常是为了反复调用它(提高代码的复用性)。
排序
PHP使用curl_multi_select解决curl_multi网页假死问题的方法
PHP使用curl_multi_select解决curl_multi网页假死问题的方法。分享给大家供大家参考,具体如下: curl_multi可以批处理事务,给网页编程带来很大的方便。不过在使用curl_multi的过程中,我们会...
php使用curl_init()和curl_multi_init()多线程的速度比较详解
php使用curl_init()和curl_multi_init()多线程的速度比较。分享给大家供大家参考,具体如下: php中curl_init()的作用很大,尤其是在抓取网页内容或文件信息的时候。 curl_init()处理事物是单线...
PHP curl批处理及多请求并发实现方法分析
PHP curl批处理及多请求并发实现方法。分享给大家供大家参考,具体如下: 在面试过程中遇到一个问题,加入一个一个网站访问一次需要两秒,我们如何实现在2秒左右请求三次? 面试官想问的就是如...
PHP中一个有趣的preg_replace函数详解
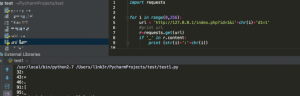
0x01 起因 事情的起因是下午遇到了 preg_replace 函数,我们都知道 preg_replace 函数可能会导致命令执行。现在我们来一些情况。 0x02 经过 踩坑1: 测试代码大概是这样的: foreach ($_GET as $...
详解mysql中的concat相关函数
一、concat()函数 功能:将多个字符串连接成一个字符串 语法:concat(str1,str2,…) 其中的字符串既可以是数据表字段,也可以是指定的字符串 返回结果为连接参数产生的字符串,如果有任何一个...
mysql基础架构教程之查询语句执行的流程详解
前言 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇文章了。 这篇笔记主要记录mysql的基础架构,一条查询语句是如何执行的。 下面话...
MySQL5.7中的sql_mode默认值带来的坑及解决方法
在正常项目开发过程中,如果MySQL版本从5.6升级到5.7版本。作为DBA在考虑数据库版本升级带来的影响时,一般会有几个注意点: sql_mode optimizer_switch 本文主要内容是MySQL升级到5.7版本之后...
MYSQL实现排名及查询指定用户排名功能(并列排名功能)实例代码
这里提供MYSQL实现排名及查询指定用户排名功能(并列排名)的SQL实例代码: 1. 全局排名 SELECT user, score, @rownum := @rownum + 1 AS rownum FROM users u, (SELECT @rownum := 0) r ORDER BY ...
PHP定时备份MySQL与mysqldump语法参数详解
介绍几个MySQL备份命令mysqldump常用操作实例: 1、mysqldump备份 只导出表结构 d:/PHP/xampp/mysql/bin/mysqldump -h127.0.0.1 -P3306 -uroot -p123456 snsgou_sns_test --no-data --default_c...
nginx配置文件详解中文版
nginx默认配置文件 nginx.conf手大部分命令,并加以中文注释说明,实际配置中可能没有这么复杂,这里只能作为一个参考阅读文档! 一、nginx基本配置 #定义Nginx运行的用户和用户组,系统中必须有...







