
大数据共66篇 第6页
大数据(big data),是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
排序
HBase主要运行机制(物理存储和逻辑架构)
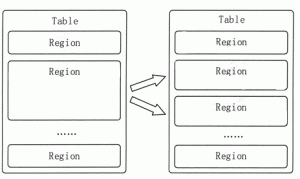
本节将对 HBase 的主要运行机制进行简单介绍。 HBase 的物理存储 HBase 表中的所有行都是按照行键的字典序排列的。因为一张表中包含的行的数量非常多,有时候会高达几亿行,所以需要分布存储到...
HBase Java API编程实例

本节通过一个具体的编程实例来学习如何使用 HBase Java API 解决实际问题。在本实例中,首先创建一个学生成绩表 scores,用来存储学生各门课程的考试成绩,然后向 scores 添加数据。 表 scores ...
数据挖掘之关联规则分析简介
关联分析是指从大量数据中发现项集之间有趣的关联和相关联系。关联分析的一个典型例子是购物篮分析。在大数据时代,关联分析是最常见的数据挖掘任务之一。 概述 关联分析是一种简单、实用的分析...
k-means聚类算法简介
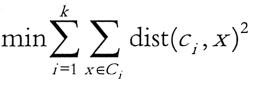
k-means 算法是一种基于划分的聚类算法,它以 k 为参数,把 n 个数据对象分成 k 个簇,使簇内具有较高的相似度,而簇间的相似度较低。 1. 基本思想 k-means 算法是根据给定的 n 个数据对象的数...
DBSCAN聚类算法简介
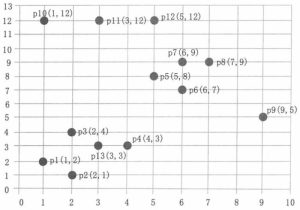
DBSCAN(Density—Based Spatial Clustering of Application with Noise)算法是一种典型的基于密度的聚类方法。它将簇定义为密度相连的点的最大集合,能够把具有足够密度的区域划分为簇,并可...
Spark Streaming的系统架构
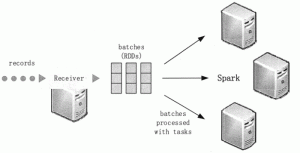
本节首先分析传统流处理系统架构存在的问题,然后介绍 Spark Streaming 的系统架构及其工作原理和优势。 传统流处理系统架构 流处理架构的分布式流处理管道执行方式是,首先用数据采集系统接收...
基于大数据的精准营销
在大数据时代到来之前,企业营销只能利用传统的营销数据,包括客户关系管理系统中的客户信息、广告效果、展览等一些线下活动的效果。数据的来源仅限于消费者某一方面的有限信息,不能提供充分的...
HBase列式数据模型简介
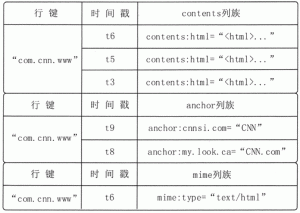
数据模型是理解一个数据库的关键,本节介绍 HBase 的列式数据模型,与数据模型相关的基本概念,并描述 HBase 数据库的概念视图和物理视图。 数据模型概述 HBase 是一个稀疏、多维度、有序的映射...
大数据在物流行业的应用
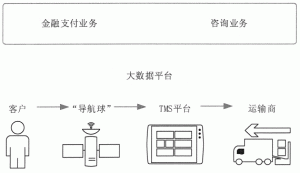
物流大数据就是通过海量的物流数据,即运输、仓储、搬运装卸、包装及流通加工等物流环节中涉及的数据、信息等,挖掘出新的增值价值,通过大数据分析可以提高运输与配送效率,减少物流成本,更有...
基于大数据的个性化推荐系统
随着互联网时代的发展和大数据时代的到来,人们逐渐从信息匮乏的时代走入了信息过载的时代。为了让用户从海量信息中高效地获取自己所需的信息,推荐系统应运而生。 推荐系统的主要任务就是联系...







